Covariates are imported into MorphoJ from text files into specific datasets.
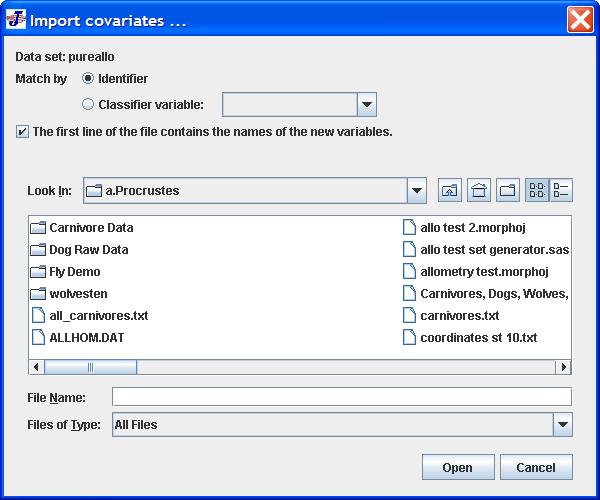
Selecting a dataset in the Project Tree tab and then choosing the menu item Import Covariates in the File menu will invoke the following dialog box:
At the top of the dialog box, a label indicates the dataset that has been chosen. The covariates will be imported to this dataset only.
The next item is a set of two buttons for choosing how the covariates are to be matched to observations in the dataset: either by the identifier or by a classifier variable. If Identifier is selected, the values of the identifier variable will be used for the match. If the button Classifier variable: is selected, however, the corresponding classifier can be selected from the drop-down menu, and its values will be used for matching.
Below this, there is a check box incating that the first line of the text file contains the names of the new variables for storing covariates. It can be deselected if the file does not contain such a first line. In this case, MorphoJ will number the covariates.
The remainder of the dialog contains the interface for selecting the file.
Clicking the Open button will invoke the loading of the file and establishing of new covariates, whereas Cancel will stop the procedure and remove the dialog box.
Entries in the file should be single numbers delimited by tab stops, commas, or semicolons. This means, the file can be prepared in a spreadsheet program and saved as tab-delimited or comma-delimited text.
The file should have the same structure as in the following example:
| ID | weight | % fruit |
| sp. 1 | 30.5 | 34 |
| sp. 2 | 40.2 | 14 |
| sp. 3 | 15 | |
| sp. 4 | 4.3 | 13 |
| sp. 5 | 53.7 | 55 |
| sp. 7 | 36.2 | 37 |
| sp. 8 | 19.4 | 27 |
| sp. 6 | 18.3 | 33 |
The first line contains the names of the covariates. The first entry ("ID" in the example above) will be ignored, but the remaining entries will be used as the names of the covariates. Each covariate should have a different name. The example would create two new covariates named "weight" and "% fruit". In principle, this line can be left out and the corresponding check box in the dialog box can be deselected, but this is probably not a good idea in most cases.
The following lines contain the actual data.
The first item is the value that is used for matching to the observations in the dataset. Depending on whether the user has chosen to match observations by the identifier or a classifier variable, these values must match either the identifier of a specimen in the dataset or the value of a classifier. The match must be exact, including spelling and the distinction upper- and lower-case letters (e.g. "sp. 4" is different from "Sp. 4" or "sp 4"), but leading and trailing blanks are ignored. Moreover, the values must be unique; if there are multiple lines with the same value for matching, only the first of these lines is used.
The second and following entries of each line must be interpretable as numbers and will be used as the covariates. Missing values (e.g., the weight for sp. 3 in the example above) are indicated by blanks or no character at all between two delimiters (in a comma-delimited file, the line for sp. 3 might appear as "sp. 3, ,15" or "sp. 3,,15").
Numbers can be integers (e.g. "34"), they can have decimals (e.g. "30.5") or they can be in scientific notation (e.g. "1.753E-09").
Missing values will be recorded by MorphoJ as 'not a number'. If they appear in outputs on the screen or in output filrs, they are written as "NaN".
After importing covariates, users may want to double-check the result by using Edit Covariates in the Preliminaries menu.